本文共 9314 字,大约阅读时间需要 31 分钟。
(这是一个系列文章:预计会有三期,第一期会以同构构建前后端应用为主,第二期会以GraphQL和MySQL为主,第三期会以Docker配合线上部署报警为主)
作者: 赵玮龙 (为什么总是我,因为有队友们无限的支持!!!)
首先声明下写这篇文章的初衷,自己也还是在全栈之路探索的学徒而已。写系列文章其一是记录下自己在搭建整站中的一些心得体会(传说有一种武功是学了就会忘记的,那就是写代码。。。),其二是希望与各位读者交流下其中遇到的坑和设计思路,怀着向即将出现的留言区学习的心态来此~~
正片的分界线
同构应用本身的优缺点我不准备在这里阐述过多,并且也一直有很多争论的方向和论点,我们在这里就不展开了。当然如果你质疑同构应用的必要性,我也并不否认比如就说得很好。那你可能会质疑为什么我还要写这个主题,原因是我们的全栈之路是能让我们做各种我们想做的事情而不受到技术的局限性。如果说我好奇他们争论的对错,顺手实现了呢?(希望你也常常抱着这样的态度去学习,那么你一定会走的更远!)
本文所有技术栈选型如下:
- node = 10.0.0
- react >= 16.3.0
- react-router >= 4.2.0
- webpack >= 4.6.0
- isomorphic-fetch >= 2.2.0
- koa >= 2.5.0
- koa-router >= 7.4.0
- react-redux >= 5.0.0
- redux >= 4.0.0
如果你发现很多写法都变了是时候更新技术栈了少年~
我们开始之前先想一下同构应用需要解决哪些问题:
- 代码兼容性(js宿主环境不一致node, browser)
- 首屏渲染
- 首屏渲染后数据同步问题
- 前后端页面路由同步
代码兼容性问题
首先项目开始时我们先想一个问题运行在 browser 端的代码可以完美的运行在 node 端吗? 当然是不能的,但是我们同构的目的不就是希望代码的复用价值提高吗?我们先想一下有哪些地方是 node 端不支持的而在 browser 端必须使用的。比如全局 window 对象 node 端是 global ,还有 v10-node 端支持基本所有ES6语法都是支持的。而 browser 端因为浏览器兼容性问题并不是这样的,但是 module 方面 node 端却不支持 import 静态引用,而浏览器端的 webpack 已经支持基于 import 的 tree shaking 了。遇到这么多兼容问题。。不得不先感叹一下js执行环境的不一致啊,都统一成v8并且去掉全局变量模块不好吗?还是要有很长路要走的。
首先配置熟悉的 .babelrc (客户端的写法我在第一篇文章中有详细的说过,可以移步)其实同构应用只需要让node端兼容import以及react的jsx就ok了。当然了如果我们之后用 Babel 自然node的代码也不会直接运行在远端机而是会编译之后再运行。这个其实除去webpack 编译打包之外还有个小问题无非是node原生模块比如 require('path') , require('stream') 我们不希望被打包,这个只需要设置 target:node webpack会帮我们忽略掉这些模块。说了这么多,我们只是希望我们之前的 .babelrc 能够打包 node 代码,所以我们只需要在入口文件添加一个钩子 @babel/register (这个@的写法是 bable7 新版本的模块写法,我的第一篇文章中有提到)。下面我来看下我们可能遇到的第一个坑,本地开发阶段我们需要在开发过程中利用自己的已有node服务去编译 webpack 文件。保证客户端的代码可以顺利执行。
const webpack = require('webpack');const logger = require('koa-logger');const config = require('./webpack.config');const webpackDevMiddleware = require('./middleware/koa-middleware-dev');const router = new Router();const app = new koa();// const Production = process.env.NODE_ENV === 'production';const compiler = webpack(config);// logger记录app.use(logger());// 替换原有的webpack-dev-middlewareapp.use(webpackDevMiddleware(compiler, { publicPath: config.output.publicPath,})); const devMiddleware = require('webpack-dev-middleware');module.exports = (compiler, option) => { const expressMiddleware = devMiddleware(compiler, option); const koaMiddleware = async (ctx, next) => { const { req } = ctx; // 修改res的兼容方法 const runNext = await expressMiddleware(ctx.req, { end(content) { ctx.body = content; }, locals: ctx.state, setHeader(name, value) { ctx.set(name, value); } }, next); };// 把webpack-dev-middleware的方法属性拷贝到新的对象函数 Object.keys(expressMiddleware).forEach(p => { koaMiddleware[p] = expressMiddleware[p]; }); return koaMiddleware} express => koares.end => ctx.body 关闭http请求链接,并且设置回复报文体res.locals => ctx.state 设置挂载穿透namespaceres.setHeader => ctx.set header设置
首屏渲染(涵盖路由同步)
首屏渲染我们要面临的问题会涉及到前后端路由同构,所以我们就放在这里一起说。服务端首屏第一步需要对于路由进行匹配(直接上代码):
// 采用koa-router的用法app.use(router.routes()) .use(router.allowedMethods());appRouter(router);// 然后设置appRouter函数module.exports = function(app, options={}) { // 页面router设置 app.get(`${staticPrefix}/*`, async (ctx, next) => { // ...内容 } // api路由 app.get(`${apiPrefix}/user/info`, async(ctx, next) => { // ...内容 }} // 我们发现为了和服务的请求api区分开我们会在路由的前缀做一下区分当然名字如你所愿 既然我们匹配了 页面/* 路由,作为单页面应用我们还需要有一个依赖的 layout 模版,先想一下模版需要哪些需要替换信息:
- 每个页面的title不同
- react操作的root节点(替换body)
- 可替换script标签内的 window对象下的__INITIAL_STATE__(这个我们会放到后面数据同步去详细说)
- 可替换的js文件(用于客户端代码执行,生产环境和线上环境的js会不一样。主要依据线上可执行代码的打包,webpack的工作,我们到后期系列-发布环节的时候会提到这个问题!)
好根据这几点我们看一下我们的 layout 模版应该是大概长什么样:
const Production = process.env.NODE_ENV === 'production';module.exports = function renderFullPage(html, initialState) { html.scriptUrl = Production ? '' : '/bundle.js'; return ` ${html.title} ${html.body} `}// 其中 scriptUrl 会根据后期上线设置的全局变量来改变。我们开发环境只是把 webpack-dev-middleware 帮我们打包好放在内存中的bundle.js文件放入html,生产环境的js文件我们后放到后期系列去说 在发送的过程中除去 scriptUrl 和 initialState 以外呢,我们需要一个可替换的 title ,以及 body 可替换的 title 我们采用 react-helmet 具体的使用方法我们就不多的赘述了。有兴趣的可以看。
在说如何塞入 body 之前我们会先去说一下整个渲染过程的流程图:
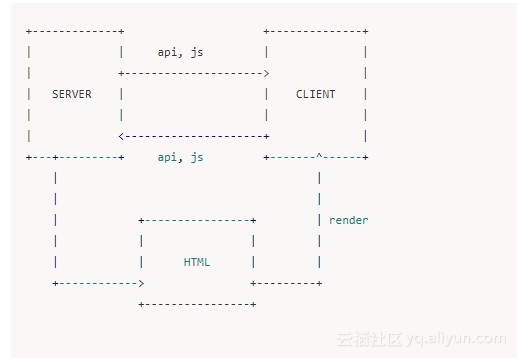
// 页面route matchexport const staticPrefix = '/page';// routes定义export const routes = [ { path: `${staticPrefix}/user`, component: User, exact: true, }, { path: `${staticPrefix}/home`, component: Home, exact: true, },];// route里的component筛选以及拿到相应component里相应的需要首屏展示依赖的fetchDataconst promises = routes.map( route => { const match = matchPath(ctx.path, route); if (match) { let serverFetch = route.component.loadData return serverFetch(store.dispatch) } })// 注意这时候需要在确认我们的数据拿到之后才能去正确的渲染我们的首屏页面const serverStream = await Promise.all(promises).then( () => { return ReactDOMServer.renderToNodeStream( ); });// 这里的关键点我们会在后面详细阐述,我们采用了react 16新的api renderToNodeStream// 正如这个api的名称一样,我们可以得到的不是一个字符串了,而是一个流// console.log(serverStream.readable); 可以发现这是一个可读流await streamToPromise(serverStream).then( (data) => { options.body = data.toString(); if (context.status === 301 && context.url) { ctx.status = 301; ctx.redirect(context.url); return ; } if (context.status === 404) { ctx.status = 404; ctx.body = renderFullPage(options, store.getState()); return ; } ctx.status = 200; ctx.set({ 'Content-Type': 'text/html; charset=utf-8' }); ctx.body = renderFullPage(options, store.getState());})// console.log(serverStream instanceof Stream); 同样你可以检测这个serverStream的数据类型 我们着重讲一下这个流的问题,还有 node 里面的异步回调的问题。 首先熟悉 node 的同学肯定对流不是很陌生了。这里我们只是概念性的说一下。如果想非常详细的了解流,建议还是去官网和别的专门说流的一些帖子比如国内的 cnode 论坛等。
流是数据的集合 —— 就像数组或字符串一样。区别在于流中的数据可能不会立刻就全部可用,并且你无需一次性地把这些数据全部放入内存。这使得流在操作大量数据或是数据从外部来源逐段发送过来的时候变得非常有用。
我们看到这个概念的时候会发现如果发送的首屏的 html 很大的话,采用流的方式反而会减轻服务端的压力。 既然 react 给我们封装了这个 api ,我们自然可以发挥它的长处。 我们来大概扫一眼可读流和可写流在 node 中有哪些 api 可用(这里我们先不去谈可读可写流)
-
可写流~ events: data ,finish , error, close, pipe/unpipe
-
可写流~ functions: write(), end(), cork(), uncork()
-
可读流~ events: data, end, error, close, readable,
-
可读流~ functions: pipe(), unpipe(), read(), unshift(), resume(), setEncoding()
这里我能用到的是可读流,上面代码中的两个 console.log() 也是帮我们确定了react的流类型。 既然是可读流我们需要发送到客户端可以利用监听事件监听流的发送和停止或者利用 pipe 直接导入到我们的可写流 res.write 上发送或者是 end() ,这里就是 pipe 方法的魔法,它pipe上游必须是一个可读流,下游是一个可写流,当然双向流也是可以的。那么思考上面的代码:
const serverStream = await Promise.all(promises).then( // ...内容);// 依然可以发送我们的可读流,但是之所以我没有这么写原因还是在于我希望动态的拼写html,并且在代码组织上把html模版单独提出一个文件res.write('My Page ')res.write(' ')serverStream.pipe(res, { end: false });serverStream.on('end', () => { res.write(" "); res.end();})// 这么做会利用流的逐步发送功能达到数据传输效率的提升。但是我个人觉得代码的耦合性比这一些性能优化要来的更加重要,这个也要根据你的个人需求来定制你喜欢和需要的模式 还有个疑问你可能比较在意我们分析下上面代码: await streamToPromise(serverStream).then( // ...内容)// 你可能觉得有点奇怪为什么我不用监听事件呢?而要把这个流包装在streamToPromise里,我是怎么拿到流的变化的呢?
这个详细的可以查看其实源码并不难。我们的目的是要让 stream 变成 promise 格式,变幻的过程当中主要是监听读写流的不同事件利用 buffer 数据格式,在各种相应的状态去做 promise 化,为什么需要这样做呢?原因还在于我们使用的koa。
我们都知道 async 函数的原理,如果你想了解更多koa的原理我还是建议看。我们这里要说明下整体原因,我们的回调函数会被 koa-router 放到 koa 的中间件use里,那么在koa中间件执行顺序中是和 async 的执行顺序一样除非你调用 next() 方法,那么如果你放在stream事件监听的回调函数里异步执行,其实这个 router 会因为你没有设置 res.end() 和 ctx.body 而执行koa 默认的代码返回404 NotFound所以我们必须在 await 里执行我们的有效返回代码!在我们有效返回我们的模版之后他会涵盖了我们的有效模版代码:
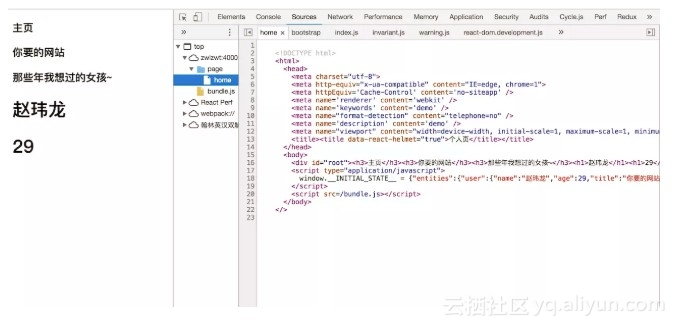
除去这些我们还会在服务端做相应的 redirect 和 4** 错误页面的一个定位转发我们响应准备好的页面:
// redirect include from to status(3**)const RedirectWithStatus = ({ from, to, status }) => ( { if (staticContext) { staticContext.status = status; } return { if (staticContext) { staticContext.status = code; } return children } } />);// 404 pageconst NotFound = () => ( Sorry, we can't find page!
);const App = () => ( { routes.map((route, index) => ( ); // 例如这样的判断if (context.status === 301 && context.url) {} 首屏渲染后数据同步问题
终于该轮到我们说数据同步的问题了,其实数据同步也非常简单。我们这里利用 redux 来做,其实不管用什么首先我们会把刚才服务端首屏渲染的数据在不通过 api 的方式放松给客户端,那么毫无疑问只有一个方法:
// 放在页面html中带过去,让客户端从window对象上拿
至于 redux 数据的生成其实跟客户端一样,如果你感兴趣可以参考
那么经过以上的种种坑过后,那么恭喜你已经有一个同构应用的雏形了。作为系列文章的开篇往往还是需要卖一个关子,完整的全栈项目 demo 会在系列完成之后给出 github 地址,敬请期待!
以上所说的所有项目中的体感,看法仅仅代表个人看法,如果你有不同的意见和自己更加独到的见解,期待在下面看到你的留言。还是那句话,希望大家在共同踩坑的同时共勉前行。也希望这里的拙见对你可能有所帮助或者启发!